We are using Continua with the database running on MS SQL Server 2019 (hosted in an availability group running on AWS).
Last week we upgraded to Continua 1.9.2.771 (from 729).
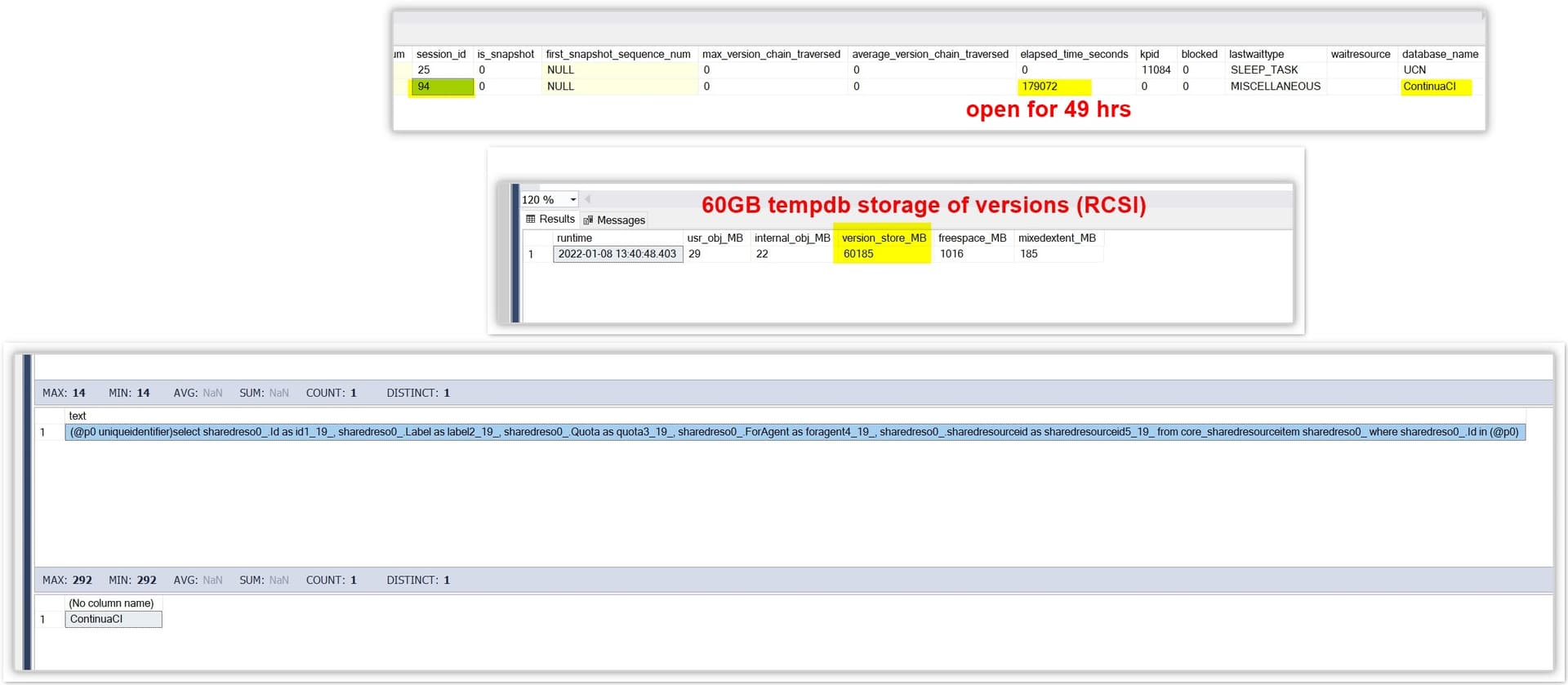
Over the weekend I received the following communication from our database administrator.
The new Continua version seems to have what is called a “rotating workload” which is a transaction that never closes by design and is constantly updating rows. This caused tempdb to fill up and throw alerts because Continua uses RCSI. I have turned off for Continua to mitigate future problems with tempdb so see how it goes with blocking/timeout errors on builds. The session had to be killed to recover the tempdb space prior to changing the RCSI state so you may have an error or process to restart.
Can you please confirm if our database admin’s analysis is correct, and also if there is any issues with turning off RCSI for the Continua database?
Continua CI uses transactions, even for selects. This is a best practice when using NHibernate (the ORM that we use). Every request, or background task creates a session, which opens a transaction, does it’s selects etc and then the transactions are either committed or rolled back before the session is disposed. I will have to check with the team lead (who is away today) on this but there should not be any long running transactions - if there are then that is something we need to look at (likely unintentional).
Continua CI does use READ_COMMITTED_SNAPSHOT isolation, this was introduced in 1.9.2.554 (so well before .729) - the release note for this says
We have not had any other reports of tempdb issues.
The application is coded with the RSCI in mind - so turning it off may or may not cause problems.
(@p0 uniqueidentifier)select sharedreso0_.Id as id1_19_, sharedreso0_.Label as label2_19_, sharedreso0_.Quota as quota3_19_, sharedreso0_.ForAgent as foragent4_19_, sharedreso0_.sharedresourceid as sharedresourceid5_19_ from core_sharedresourceitem sharedreso0_ where sharedreso0_.Id in (@p0)
Version 1.9.2.781 ensures that the transaction does not remain open for the query you identified. Please let us know if you find any other database issues.
Our database admin may have discovered another RCS issue:
I think their RCS bug is back. I’m going to need to kill the session stuck and remove RCS on that DB
You can send them this code: (@p0 nvarchar(128),@p1 nvarchar(128))select serverprop0_.Id as id1_18_, serverprop0_.Namespace as namespace2_18_, serverprop0_.Name as name3_18_, serverprop0_.Value as value4_18_, serverprop0_.CollectedValue as collectedvalue5_18_, serverprop0_.ElementType as elementtype6_18_, serverprop0_.IsUserSupplied as isusersupplied7_18_, serverprop0_.ReadOnly as readonly8_18_, serverprop0_.Description as description9_18_, serverprop0_.CollectorId as collectorid10_18_ from core_serverproperty serverprop0_ where serverprop0_.Namespace=@p0 and serverprop0_.Name=@p1 ORDER BY CURRENT_TIMESTAMP OFFSET 0 ROWS FETCH FIRST 1 ROWS ONLY
this code is not completing or not committed
We are using Continua 1.9.2.902 (updated this morning) on MS SQL Server 2019.
Thank you for sending the SQL query, we’ve found a possible cause but need to investigate further. Hopefully we’ll be able to provide a fix in the next day or two.
Our database admin is concern that this problem has reoccurred. In his words:
Yeah, maybe tell them its twice now (I hope not the same code) and it can literally take down an entire server as tempdb saturates all space. Luckily we monitor a lot of resources and can see it ahead of time but many companies would be blind to it, and few companies probably have massive tempdbs like we do.
I’m glad we’ve been able to help you zero in on the cause. Looking forward to getting the fix.
We have uploaded a hotfix version 1.9.2.904. Despite the two build number increments, this version includes only one change over v1.9.2.902 to hopefully fix this issue.
We were not able to detect any log running transactions in v1.9.2.902 either using the Activity Monitor or with SQL queries against sys.dm_exec_query_stats, but while reviewing the code found that we had inadvertently referenced a database session in a separate thread. Perhaps your database admin could share the SQL query that he uses to detect this issue?
It’s good to hear that it work. Thanks for sending the query to the sys.dm_tran_active_snapshot_database_transactions table - it does show up the stuck transaction id for us in v1.9.2.902.